
Four Key Considerations When Running PHP Applications On Multiple Servers
PHP Performance
BONUS: We have discussed this topic with an expert in the PHP community in our podcast:
Building and deploying PHP applications on one server is a, relatively, straightforward process. However, what about deploying a PHP application across multiple servers? In this article, I’m going to discuss four key considerations to bear in mind when deploying PHP applications when doing so.
Load Balancing
Load balancing is where requests are distributed uniformly across servers in a server pool. Load balancers receive user requests and determine which server in a server pool to forward the request for final processing. They can either be hardware- (e.g., F5 Big-IP, and Cisco ACE) or software-based (e.g., HAProxy, Traefik, and Nginx).
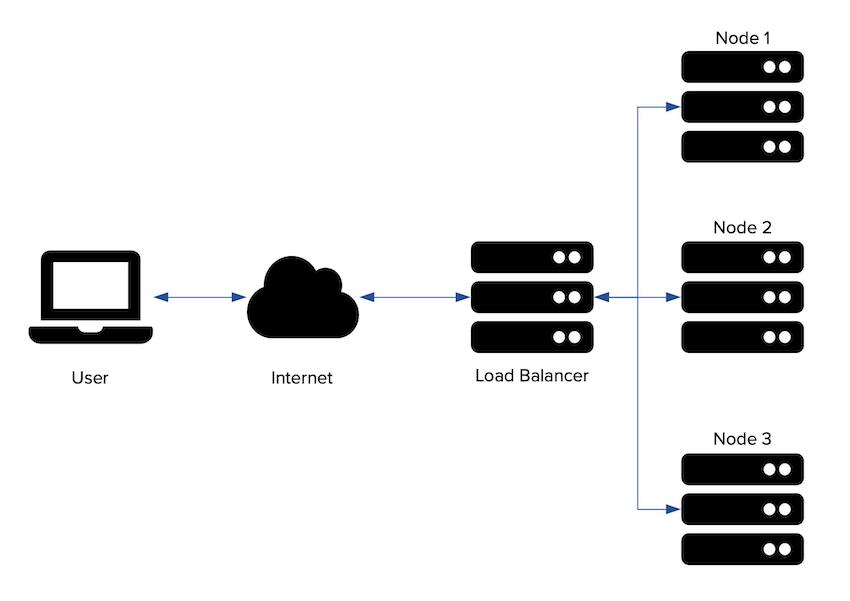 Simple load balancer diagram
Simple load balancer diagram
Using them increases network efficiency, and application reliability and capacity, by adding servers on a planned basis or to meet short-term demand. In applications that use them, users never know that the same server isn’t handling their requests every time. All they know is that their requests are handled.
Load balancers typically use one of six methods for determining the server to pass a given request. These are:
- Round Robin: Requests are distributed evenly across all servers in the pool.
- Least Connections: Requests are sent to the server with the least number of currently active requests.
- IP Hash: Requests are routed based on the client’s IP Address.
- Generic Hash: Requests are routed based on a user-defined key.
- Least Time: Requests are sent to the server with the lowest latency.
- Random: Requests are distributed randomly across all servers in the pool.
While the benefits are many, migrating a load balanced-architecture requires a number of factors to be considered, which include:
- Does each server in the cluster have the same physical capacity?
- How Are Nodes Upgraded?
- What Happens if a Node Is Unreachable or Fails?
- What Kind of Monitoring Is Required?
These, and other questions, need answering before choosing and implementing the correct load balancer. That said, if you’re going to setup load balancing yourself, I strongly encourage you to use NGINX, as it’s likely the most used option. You can find out how to get started with NGINX’s load balancing documentation.
Sessions
Now that we’ve considered load balancing, the next logical consideration is: how are sessions handled? Sessions allow applications to get around HTTP’s stateless nature and preserve information across multiple requests (e.g., login status and shopping cart items).
By default, PHP stores sessions on the filesystem of the server which handles the user’s request. For example, if User A makes a request to Server B, then User A’s session is created and stored on Server B.
However, when requests are shared across multiple servers, this configuration likely results in broken functionality. For example:
- Users may be part-way through a shopping cart and find that their cart is unexpectedly empty
- Users may be randomly redirected to the login form
- Users may be part-way through a survey only to see that all their answers have been lost
There are two options to prevent this:
- Centrally-stored sessions; and
- Sticky sessions
Centrally Stored Sessions
Sessions can be centrally stored by using a caching server (e.g., Redis or Memcached), a database (e.g., MySQL or PostgreSQL), or a shared filesystem (e.g., NFS or [Glusterfs]). Of these options, the best is a caching server. This is for two reasons:
- They’re a key-value, in-memory storage solution, which gives them greater responsiveness than an SQL database.
- As sessions are always written when a request ends, SQL databases must write to the database on every request. This requirement can easily can lead to table locking and slow writes.
When storing sessions centrally, you need to be careful that the session store doesn’t become a single point of failure. This can be avoided by setting up the store in a clustered configuration. That way, if one server in the cluster goes down, it’s not the end of the world, as another can be added to replace it.
Sticky Sessions
An alternative to session caching is Session Stickiness (or Session Persistence). This is where user requests are directed to the same server for the lifetime of their session. It may sound like an excellent idea at first, but there several potential drawbacks, including:
- Will cold and hot spots develop within the cluster?
- What happens when a server isn’t available, is over-burdened, or has to be upgraded?
For these reasons, and others, I don’t recommend this approach.
Shared Files
How will shared files be updated? To make things just that much trickier, there are, effectively, two types of shared files:
- User-provided files and one-off items, such as PDF invoices.
- Code files and templates.
These need to be handled in different ways. Let’s start with code files and templates.
These types of shared files need to be deployed to all servers when a new release or patch is made available. Failing to do this will see any number of unexpected functionality breaks.
The question is: what’s the best approach to deploy them? You can’t take down and update nodes individually. Why? What happens if users are directed to a server with new code on one request and directed to a server with the old code on a subsequent request? Answer: broken functionality.
One solution is to change the load balancer method to stop directing requests to nodes during updates. After nodes are updated, they’re allowed to accept new session requests.
This could then be repeated until all nodes within the cluster have been upgraded or patched. It’s workable, but it’s also, potentially, quite complicated and time-consuming.
Now let’s look at user provided and one-off files. These types of files, include images, such as a profile image PDF invoices, and company/organizational reports. These types of files need a shared filesystem, whether local or remote (such as S3).
Some potential solutions are a clustered filesystem such as Glusterfs, or a SaaS solution, such as Amazon S3, or Google Cloud Storage.
A shared (clustered) filesystem simplifies deployment processes, as new releases and patches, only need to update files in one location. The deployment process likely doesn’t need to handle file replication to each node within the filesystem cluster, as the service should provide that.
However, like centrally stored sessions, the filesystem has the potential to become a single point of failure, if it goes down or becomes inaccessible. So, this needs to be considered and planned for as well.
Implementing one of these solutions allow files to be centrally located, where each node can directly access it, as and when required. Many of PHP’s major frameworks (including Laravel, Symfony, and Zend Expressive) natively support this approach. Alternatively, packages such as Flysystem can help you implement this functionality in your application.
Job Automation
It’s quite common in modern applications — especially in PHP — to use Cron to automate regular tasks. These can be for any number of reasons, including file cleanup, cleanup abandoned shopping carts, email processing, and user account maintenance.
However, if the application is composed of multiple nodes, there are several questions to consider. For example:
- Which server does Cron run on?
- Does the Cron service run on a separate server from the web application?
- If one server is dedicated to running Cron tasks:
- What happens when it goes down, say because of a hardware failure?
- What happens when it’s taken down for maintenance?
- What happens when it’s not accessible?
You could roll your own solution, or you could use one of several existing solutions, such as Dkron or Apache Mesos and Airbnb Chronos. Each of these has its pros and cons.
If you roll your own solution, it may be a lot of work in addition to your existing application. It may lead you to experience the same multi-server considerations that we’re currently discussing. Alternatively, if you use one of the above solutions, you will need to plan out the implementation and maintenance of that server and how to best integrate it with your application.
All of these are viable approaches. It’s just important to consider this in advance.
In Conclusion
Those are four key considerations to keep in mind when transitioning from a single to a multi-server setup. There are others in addition to these four.
However, these are four of the most important. I hope that they provide a sound foundation for helping you to understand the potential changes and pitfalls involved.
About the author

I am the founder and CEO of Tideways. I started the company over 10 years ago with the mission to move the PHP ecosystem forward, starting with performance. As managing director, I work across product, strategy, and the day-to-day of building a developer-focused SaaS business.
I’m a core contributor to the Doctrine open-source project and a founding board member of the PHP Foundation, which reflects my long-standing commitment to the PHP ecosystem. I particularly enjoy working at the intersection of application performance, developer experience, and the open-source community that makes PHP what it is. Outside of work, I enjoy board games, hiking, and coffee.